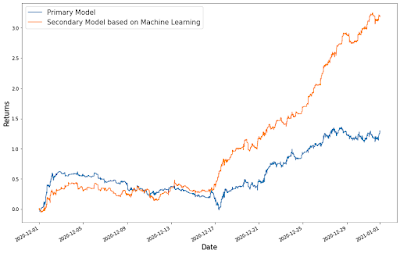
By Sergei Belov, Ernest Chan, Nahid Jetha, and Akshay Nautiyal
We applied
Corrective AI (Chan, 2022) to a trading model that takes
advantage of the intraday seasonality of forex returns. Breedon and Ranaldo
(2012) observed that foreign currencies
depreciate vs. the US dollar during their local working hours and appreciate
during the local working hours of the US dollar. We first backtested the
results of Breedon and Ranaldo on recent EURUSD data from September 2021 to
January 2023 and then applied Corrective AI to this trading strategy to achieve
a significant increase in performance.
Breedon and Ranaldo (2012) described a trading
strategy that shorted EURUSD during European working hours (3 AM ET to 9 AM ET,
where ET denotes the local time in New York, accounting for daylight savings)
and bought EURUSD during US working hours (11 AM ET to 3 PM ET). The rationale
is that large-scale institutional buying of the US dollar takes place during
European working hours to pay global invoices and the reverse happens during US
working hours. Hence this effect is also called the “invoice effect".
There is some supportive evidence for the
time-of-the-day patterns in various measures of the forex market like
volatility (see Baille and Bollerslev(1991), or Andersen and Bollerslev(1998)),
turnover (see Hartman (1999), or Ito and Hashimoto(2006)), and return (see
Cornett(1995), or Ranaldo(2009)). Essentially,
local currencies depreciate during their local working hours for each of these
measures and appreciate during the working hours of the United States.
Figure 1 below describes the average hourly
return of each hour in the day over a period starting from 2019-10-01 17:00 ET
to 2021-09-01 16:00 ET. It reveals the pattern of returns in EURUSD. The return
pattern in the above-described “working hours'' reconciles with the hypothesis
of a prevalent “invoice effect” broadly. Returns go down during European
working and up during US working hours.
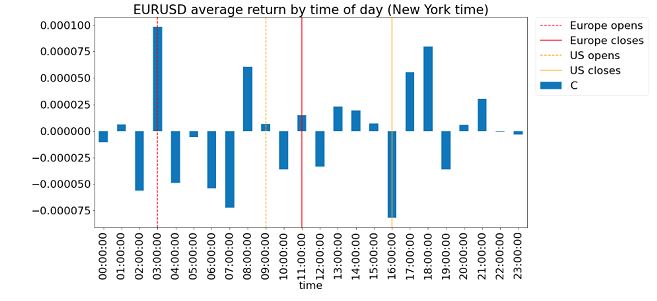
Figure
1: Average EURSUD return by time of day (New York time)
As this strategy was published in 2012, it
offers ample time for true out-of-sample testing. We collected 1-minute bar
data of EURUSD from Electronic Broking Services (EBS) and performed a backtest
over the out-of-sample period October 2021-January 2023. The Sharpe Ratio of
the strategy in this period is 0.88,
with average annual returns of 3.5% and a maximum drawdown of -3.5%. The alpha
of the strategy apparently endured. (For the purpose of this article, no
transaction costs are included in the backtest because our only objective is to
compare the performances with and without Corrective AI, not to determine if
this trading strategy is viable in live production.)
Figure 2 below shows the equity curve (“growth
of $1”) of the strategy during the aforementioned out-of-sample period. The
cumulative returns during this period are just below 8%. We call this the
“Primary” trading strategy, for reasons that will become clear below.
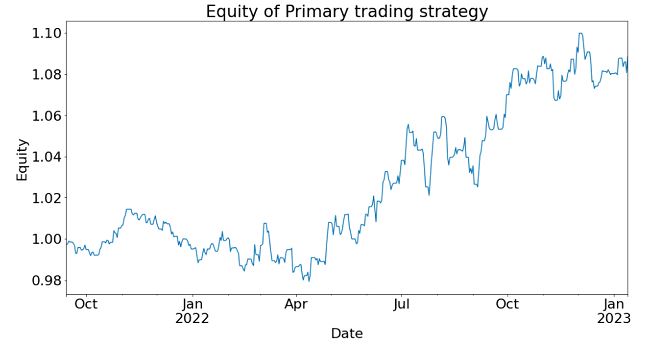
Figure
2: Equity curve of Primary trading strategy in out-of-sample period
What is
Corrective AI?
Suppose
we have a trading model (like the Primary trading strategy described above) for
setting the side of the bet (long or short). We just need to learn the size of
that bet, which includes the possibility of no bet at all (zero sizes). This is
a situation that practitioners face regularly. A machine learning algorithm
(ML) can be trained to determine that. To emphasize, we do not want the ML
algorithm to learn or predict the side, just to tell us what is the appropriate
size.
We
call this problem meta-labeling (Lopez de Prado, 2018) or Corrective AI (Chan,
2022) because we want to build a secondary ML model that learns how to use a
primary trading model.
We
train an ML algorithm to compute the “Probability of Profit” (PoP) for the next
minute-bar. If the PoP is greater than 0.5, we will set the bet size to 1;
otherwise we will set it to 0. In other words, we adopt the step function as
the bet sizing function that takes PoP as an input and gives the bet size as an
output, with the threshold set at 0.5.
This bet sizing function decides whether to take the bet or pass, a
purely binary prediction.
The
training period was from 2019-01-01 to 2021-09-30 while the out-of-sample test
period was from 2021-10-01 to 2023-01-15, consistent with the out-of-sample
period we reported for the Primary trading strategy. The model used to train ML
algorithm was done using the predictnow.ai Corrective AI (CAI) API, with more
than a hundred pre-engineered input features (predictors). The underlying
learning algorithm is a gradient-boosting decision tree.
After applying Corrective AI, the Sharpe Ratio
of the strategy in this period is 1.29
(an increase of 0.41), with average annual returns of 4.1% (an increase
of 0.6%) and a maximum drawdown of -1.9%
(a decrease of 1.6%). The alpha of the strategy is significantly improved.
The equity curve of the Corrective AI filtered
secondary model signal can be seen in the figure below.
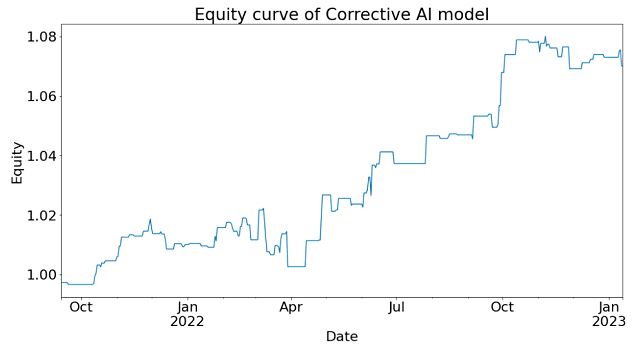
Figure
3: Equity curve of Corrective AI model
in out-of-sample period
Features used to train the Corrective AI model include technical
indicators generated from indices, equities, futures, and options markets. Many
of these features were created using Algoseek’s high-frequency futures and equities
data. More discussions of these features can be found in (Nautiyal & Chan,
2021).
Conclusion:
By applying Corrective AI to the
time-of-the-day Primary strategy, we were able to improve the Sharpe ratio and
reduce drawdown during the out-of-sample backtest period. This aligns with
observations made in the literature on meta-labeling for our primary
strategies. The Corrective AI model's signal filtering capabilities do enhance
performance in specific scenarios.
Acknowledgment
We are grateful to Chris Bartlett of Algoseek,
who generously provided much of the high-frequency data for our feature
engineering in our Corrective AI system. We also thank Pavan Dutt for his
assistance with feature engineering and to Jai Sukumar for helping us use the
Predictnow.ai CAI API. Finally, we express our appreciation to Erik MacDonald
and Jessica Watson for their contributions in explaining this technology to
Predictnow.ai’s clients
References
Breedon,
F., & Ranaldo, A. (2012, April 3). Intraday
Patterns in FX Returns and Order Flow. https://ssrn.com/abstract=2099321
Chan,
E. (2022, June 9). What is Corrective AI?
PredictNow.ai. Retrieved February 23, 2023, from
https://predictnow.ai/what-is-corrective-ai/
Lopez
de Prado, M. (2018). Advances in
Financial Machine Learning. Wiley.
Nautiyal,
A., & Chan, E. (2021). New Additions
to the PredictNow.ai Factor Zoo. PredictNow.ai. Retrieved February 28,
2023, from https://predictnow.ai/new-additions-to-the-predictnow-ai-factor-zoo/